
Anchor-based Object Detection의 설계
Faster R-CNN, RetinaNet, YOLOv2, SSD 등 다양한 Object Detection 아키텍처들은 정확도를 높이기 위해 사전에 정의된 Anchor라는 개념을 도입하고 있습니다. 아무런 전제 조건이 없는 상태에서 물체의 위치와 크기를 학습하기보다는, 대부분의 물체들은 어느 정도 일반적인 형태를 가지고 있으므로 그러한 출발점(Anchor)을 미리 정의해놓고 그로부터 Regression을 하면 보다 빠르게 학습하며 정확히 물체를 탐지할 수 있다는 것입니다.

예를 들어 봅시다. 만약 Feature Map이 원래 이미지보다 1/4로 줄어들었다면 Feature Map의 각 픽셀마다 $4\times 4$의 크기를 갖는 가장 단순한 형태의 Anchor를 정의할 수 있을 것입니다. 이 Anchor와의 IoU를 계산해 Positive Sample, Negative Sample을 정의하고, Regression 또한 해당 Positive Anchor와 Ground-Truth 간의 차이, $\Delta x, \Delta y, \Delta w, \Delta h$ 를 예측하는 것으로 수행됩니다.
여기서 좀 더 다양한 형태의 물체를 고려하기 위해 Anchor를 Aspect Ratio와 Scale에 따라 다양하게, 그리고 더 많이 설정합니다. 일반적으로 Faster R-CNN과 같은 Two-Stage 계열은 Aspect Ratio는 [1:2, 1:1, 2:1]으로, 그리고 Feature Pyramid에서 사용하는 Feature Map $\{ P_2, \dots, P_6 \}$ 마다 Stride에 따른 Scale을 설정하여 $3 \times 5$에 해당하는 전체 15 종류의 Anchor를 사용합니다. 추가적으로 위의 간단한 예시에선 Stride를 그대로 Anchor 크기로 계산하였지만 일반적으로 $ Stride \times 8 $에 해당하는 크기로 Anchor의 크기를 설정합니다.

Ground-Truth와 IoU가 특정 값 이상인 Anchor들을 Positive Sample로 정의하고, Positive Sample로 매칭된 Anchor와 Ground Truth 간의 차이인 Delta Target을 계산하여, 모델은 이러한 Positve, Negative sample (Class) 분류와 Delta Target을 예측하는 방향으로 학습이 됩니다.
추가적으로 이렇게 한 픽셀 위치에 여러 개의 Anchor를 할당하는 방식은 1) 여러 물체가 한 위치에 겹쳐있을 때도 각각의 물체를 서로 다른 Anchor에 Mapping하는 역할과 2) 하나의 Target 물체에 대해 여러 Anchor가 Mapping되게 함으로써 Positive Sample의 비율을 늘려 학습을 용이하게 하는 역할을 합니다.
Anchor-based Object Detection의 한계
물체에 대한 아무런 전제 조건 없이 Regression을 하는 게 아니라, 물체의 형태에 대한 사전 정보(Prior)를 직접 설계하여 정확도를 향상시킨 Anchor-Based Architecture는 한동안 Object Detection에서 불문율 또는 De Facto처럼 여겨져 왔습니다.
하지만 Image Classification, Semantic Segmentation은 대부분 CNN으로 구성될 수 있는 단순한 아키텍처와 달리 복잡한 형태를 갖는 Object Detection을 단순화하고, 사람이 갖는 Inductive Bias를 제거하고서도 높은 성능을 보여주는 Architecture에 대한 갈망이 연구자들을 이끌었습니다.
Hand-crafted Anchor 설계의 어려움

Anchor-based Object Detector의 대표적인 한계점으로, 물체의 특정한 형태를 가정하고 Anchor를 사전에 설계했기 때문에 위와 같이 [1:2, 1:1, 2:1]과 크게 벗어나는 물체를 탐지해야 할 때 Anchor가 아무 쓸모가 없거나 오히려 학습에 방해가 될 수도 있다는 점이 있습니다. 물론 이러한 데이터의 레이블들을 미리 읽어 통계를 이용해 새로 Anchor를 정의하는 방법도 있지만, 모든 데이터에 이렇게 대응하는 것은 번거로운 일이면서도 적합한 Anchor를 찾기 위해 Hyperparameter Search를 매번 해야 하는 것은 연구자, 엔지니어 모두에게 부담이 될 것입니다.
Anchor related Computation Cost
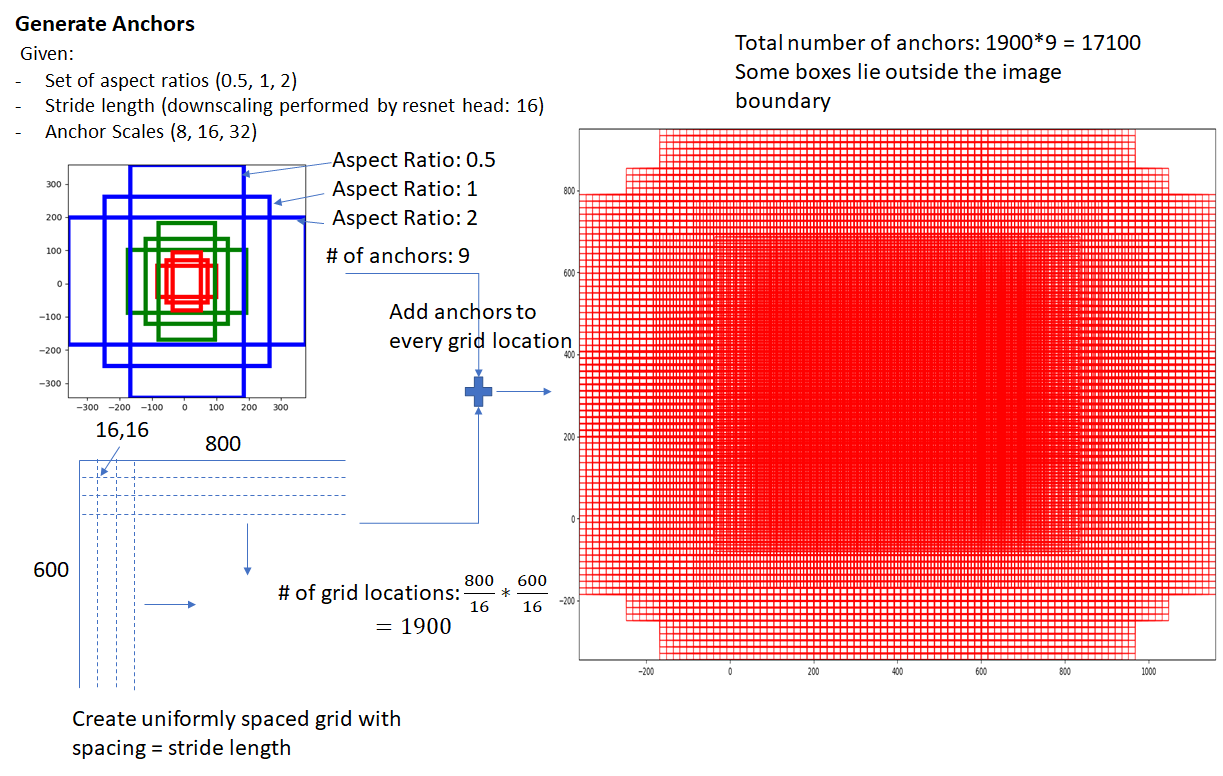
Anchor를 사용하게 되면 위와 같이 Scale을 단지 3개만 고려해도 수많은 Anchor들을 생성하고, 이에 따라 Ground-Truth, Prediction과 비교하는 IoU Computation이 굉장히 크게 늘어나게 됩니다. 또한 하나의 Target에 대해 여러 개의 Anchor가 Positive Sample로 매칭되기 때문에 인퍼런스할 때도 마찬가지로 하나의 Object에 대해 여러 개의 Prediction을 수행하므로 중복된 Box를 제거하는 Non-maximum Suppression (NMS) 수행을 필요로 합니다. 이는 Anchor를 사용하면 학습할 때뿐만 아니라 인퍼런스 시에도 추가적인 Computation Cost를 부담해야 함을 의미합니다.
High Complexity to Enhance Architecture

Object Detection의 Hand-crafted Design의 복잡성은 연구자들에게도 엔지니어들에게도 Object Detection에 대한 진입장벽이 되기도 합니다. 위 사진과 같이 Object Detection 모델의 소스코드는 Anchor Matching 등 복잡한 로직을 동반하며, 서로 다른 기능을 하는 여러 Module들이 맞물려 있기 때문에 Image Classification이나 Semantic Segmentation의 소스코드와 비교할 때 상대적으로 전체 구조를 파악하기 어려운 점이 있습니다.
코드뿐만 아니라 다양한 모듈들이 서로 긴밀하게 의존하고 있기 때문에, 몇몇 연구자나 엔지니어들에게 Object Detection이라는 문제가 연구적으로 문제점을 진단하고 이를 개선하거나 해결하기보다는 복잡한 구조 속에서 여러 모듈들을 끼우고 바꾸는 Trial and Error를 통해서나 개선할 수 있는 문제라는 인상을 남기기도 했습니다.
Anchor-free Object Detection
위와 같은 이유들로 Hand-crafted Design을 최대한 배제한 채 좀 더 단순한 아키텍처 형태로 Object Detection을 해결하려는 시도들이 연구되었습니다.
사실 YOLOv1 모델도 Anchor-free 아키텍처였지만 Anchor를 기본적으로 탑재하는 당시의 SOTA 모델들과 비교할 때 YOLOv1는 성능이 너무 낮았습니다. 이러한 이유로 Object Detection에서 당시 SOTA 모델들의 성능을 준수하게 따라가면서도 Anchor를 제거한 아키텍처 설계에 대한 연구가 주목을 받기 시작했습니다.
여러 방법론들이 제안되어 왔지만 본 글에서는 현재에도 후속 연구가 발표되며, Object Detection 문제를 새롭게 정의하려는 시도들을 다룬 연구들 중 몇 개만을 다뤄보고자 합니다.
- FCOS: Fully Convolutional One-Stage Object Detection (ICCV 2019)
- Objects as Points (arXiv 2019)
- RepPoints: Point Set Representation for Object Detection (ICCV 2019)
- Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection (CVPR 2020)
FCOS (ICCV 2019)

FCOS: Fully Convolutional One-Stage Object Detection
현재에도 널리 사용되는 Anchor-Free Architecture의 원형이자 당시 Anchor-based One-Stage Object Detection로서 SOTA에 가깝던 RetinaNet의 성능을 추월한 FCOS입니다.
FCOS는 이름과 같이, 딥 러닝 기반 Semantic Segmentation 모델의 원형인 FCNN(Fully Convolutional Neural Network model)과 유사하게 오직 Convolution Layer로만 구성된 아키텍처입니다.

아이디어는 간단합니다. FCNN와 유사하게 모든 픽셀에서 물체의 Bounding Box 안에 픽셀의 좌표가 포함되면 해당 물체로 Classification을 합니다. 거기에 더해 해당 위치로부터 물체의 Bounding Box의 경계까지 얼마큼의 거리인지를 Left(l), Top(t), Right(r), Bottom(b)으로 표현하여 4D vector를 동시에 Regression합니다. 즉 FCNN 형태로 Feature Map의 모든 픽셀마다 Classification Score와 4D Vector [l,t,r,b]를 예측하는 것입니다.
추가적으로 1) 겹친 물체에 대하여 학습 및 인퍼런스를 하기 위해 FPN(Feature Pyramid Network)을 해결책으로 도입하고, 2) 물체의 중심과 먼 거리에 있는 Prediction들이 낮은 성능을 가져 물체의 중심에 가까운 Prediction만을 활용하기 위해 Center-ness 브랜치를 도입합니다.

Anchor-based Architecture에선 각 Feature Map마다 Anchor의 크기들이 결정되고 IoU Computation을 이용해 Ground-Truth를 각 Feature Map에서 적절한 Scale의 Anchor에 매핑합니다. 반면에 FCOS에선 Anchor에 대한 IoU Computation 과정 등이 따로 없기 때문에 Ground-Truth를 할당할 때 미리 정의한 크기에 맞춰서 각 Feature Map에 할당합니다. 이렇게 함으로써 어느 정도 물체가 겹쳐져 있다고 하더라도 서로 다른 Feature Map에서 서로 다른 크기의 물체를 탐지하도록 학습되었기 때문에 각각의 물체들에 대해 탐지가 가능합니다.

Center-ness 브랜치는 간단하게 $ (l^\ast, t^\ast, r^\ast, b^\ast) $ 값에 따라 중심에 가까울수록 1, 중심과 멀어질수록 0에 가까운 값을 예측하도록 학습됩니다. 학습 당시에는 Regression 브랜치나 Classification 브랜치와 완전히 별도로 학습되는데, 인퍼런스 시에는 해당 픽셀에 해당하는 Classification Score에 Center-ness를 곱해주는 방식으로 NMS 시에 최종 Score가 떨어지는 Prediction들이 필터링되도록 사용됩니다.

아키텍처를 제외한 다른 요인들을 정확히 일치시킨 상태에서 비교한 것은 아니지만, 당시 SOTA 모델들을 뛰어넘는 성능을 보여주었습니다.
(참고로 Two-Stage 아키텍처인 Faster R-CNN의 성능은 구현체마다 성능이 상이하기 때문에 당시 기준으로선 Detectron의 벤치마크를 참고하는 게 좋습니다. ResNet-101-FPN 기준 AP 39.0. 현재에 와선 detectron2 벤치마크와 비교하는 게 보다 적절합니다. ResNet-101-FPN 기준 AP 42.0. )
CenterNet (arXiv 2019)

CenterNet은 FCNN과 같이 대부분 Convolution Layer만으로 모델을 구성하면서, FCOS보다도 Object Detection 문제를 간단히 정의하였습니다. Semantic Segmentation과 같이 Bounding Box에 해당하는 영역에 대해 모두 Classification하기보다는, 물체의 중심에 대해서만 Positive Sample로 할당하여 이를 예측하는 Class Heat Map을 학습하고, 이렇게 예측한 Keypoint 들에 대해서만 Regression 예측값을 인퍼런스 결과로 사용하는 것입니다. 여기서 Object를 Center Point로 정의했기 때문에 FCOS와 달리 중심으로부터의 [width, height]에 대한 값으로 Object Size를 학습합니다. 추가적으로 예측한 Keypoint의 좌표를 좀 더 정확하게 보정하기 위해 별도의 offset 또한 학습합니다.

이러한 아키텍처로 인해 낮은 퀄리티의 Prediction을 제거하기 위한 Center-ness 브랜치와 같은 모듈들을 별도로 필요로 하지 않습니다. 또한 수많은 Prediction Box들 간에 NMS를 하는 대신, Max Pooling을 활용해 Center Point가 뭉쳐있을 때 가장 Score가 높은 픽셀에 대해서만 인퍼런스 결과를 활용함으로써 FCOS와 비교할 때 굉장히 간단하면서도 빠르게 인퍼런스가 가능합니다.
다만 일반적인 모델들과 달리 FPN을 사용하지 않고, FCOS와 달리 중심이 어느 정도 겹쳐 있는 물체들에 대한 해결 방법을 고려하지 않은 것은 다소 아쉽습니다.

사실 발표된 당시만 하더라도 Hourglass Net과 같이 굉장히 무거운 Backbone을 써야 RetinaNet보다 조금 더 나은 성능을 얻었기 때문에 Object Detection Architecture 자체로선 엄청 큰 관심을 끌진 못했습니다.

다만 최근에 이러한 CenterNet을 RPN으로 활용하여 2-Stage로 설계한 CenterNet2가 매우 높은 성능을 달성하면서 다시 주목해볼만한 여지가 생겼습니다.
RepPoints (ICCV 2019)

RepPoints: Point Set Representation for Object Detection
일반적으로 딥 러닝 계열의 Object Detection 모델들은 물체를 나타내기 위해 Bounding Box를 주로 이용하였습니다. 하지만 Bounding Box는 실제로는 물체가 없는 경계까지 포함하기 때문에 물체 탐지를 위해 굳이 필요로 하지 않는 Representation까지 학습할 가능성이 남아있습니다.
만약 그렇다면 Bounding Box의 경계 전체를 Object의 Representation으로 표현하는 게 아니라, Object의 주요 Edge Point들로 Representation을 나타낸다면 어떨까요? 그리고 과연 Bounding Box Annotation으로부터 이러한 Representation을 학습하는 게 가능할까요?
RepPoints는 이러한 관점에서 Localization과 Recongition 모두를 향상시키기 위해 Bounding Box 대신 RepPoints (representative points)를 이용해 물체를 정의합니다. 그리고 놀랍게도 Bounding Box 어노테이션만으로도 물체의 의미론적으로 중요한 경계 Point(the spatial extent of an object)에 대해 학습 및 인퍼런스가 가능하다는 걸 보입니다.
어떻게 이런 게 가능한 걸까요? RepPoints는 이러한 목적을 달성하기 위해서 물체의 의미론적으로 중요한 Feature를 알아서 학습한다고 알려진 Deformable Convolution을 활용합니다.

Deformable Convolution은 기존 Convolution이 사람이 사전에 정의한 Kernel의 형태로 Sampling하는 픽셀 좌표가 고정된 채로 학습한다는 한계를 극복하기 위해, Feature를 Sampling할 좌표 자체를 같이 예측하는 형태로 설계한 Layer입니다.
이러한 Sampling Location 또는 Offset은 별도의 Supervision이 없어도 물체의 중요 특징을 찾아가도록 알아서 학습이 됩니다. 만약 Sampling하는 좌표의 Feature Vector가 물체를 잘 나타내지 못한다면 이는 Recognition 또는 Localization에 악영향을 줄 것이고 결국 Loss를 키울 것입니다. 즉 별도의 Supervision이 없다고 하더라도 Loss를 줄이기 위해 더 좋은 Feature Vector를 Sampling하는 좌표를 예측하는 방향으로 학습이 되는 것입니다.


RepPoints는 이러한 Deformable Convolution의 성질을 그대로 활용합니다.

먼저 Deformable Convolution을 이용하여 모든 Feature Map에서 각각 Offset을 예측합니다. 이렇게 예측된 Offset, 즉 Representative Points들을 이용해 최종적으로 Convolution을 거쳐 Classification을 합니다.
Regression의 경우 Representative Points들의 [min_x, min_y, max_x, max_y]을 이용해 Bounding Box를 만든 후 Ground-Truth와 비교하여 Loss를 줍니다. 여기에 더해 추가적으로 처음 뽑아놓았던 Representative Points들에 대해 추가적으로 Offset을 예측하여 Sampling Point를 개선하고 이에 대해서도 Loss를 부여합니다.

이러한 과정을 통해 모델을 학습하여, 위와 같이 최종 Representative Points들을 시각화하면 Bounding Box Supervision만 주어졌음에도 불구하고 어느 정도 물체의 경계면들을 참조하는 것을 확인할 수 있습니다.

Anchor-based냐 Anchor-Free냐 무엇이 문제인가
지금까지 다양한 방식으로 Anchor-Free Object Detection 아키텍처를 설계한 연구들을 살펴보았습니다. 이 연구들은 다양한 방식으로 Anochor-Free 아키텍처에서 Object Detection을 수행하기 위해, SOTA 성능을 달성하기 위해 여러 가지 방법들을 도입했지만, Anchor-based 아키텍처와 완전히 동일한 구조 하에서 Ablation Study를 통한 비교를 한 적은 없었습니다.
즉, Anchor-Free 아키텍처로서도 Object Detection이 가능하다는 것을 보였다는 점에선 큰 의의가 있지만, 이러한 연구들이 말하는 성능들이 과연 Anchor-Free 아키텍처로 인해 기인한 것인지 아니면 Loss, Centerness, Scaling Parameter 등 부가적인 요인으로 인한 것인지 알 수 없다는 것입니다.
그리고 근본적으로 Anchor-Free와 Anchor-based 아키텍처가 Learning 관점에서 어떠한 차이점을 만들어내는지 분석하는 연구가 부족한 상황이었습니다.
사실 FCOS나 CenterNet을 보면 YOLOv1과 비교했을 때 구조적으론 큰 차이가 나지 않는 것으로 보이는데 무엇이 큰 성능 차이를 만들어내는 걸까요? FCOS와 CenterNet은 Object Detection 문제를 정의하는 방식만 다를 뿐인데 성능 차이가 왜 이렇게 큰 것일까요? 구현 차이에 대한 이슈는 없는 걸까요?
Anchor에서 시작해서 Regression하는 거나 Point로부터 시작해서 Regression하는 게 그렇게 큰 차이를 만들어내는 걸까요? Anchor를 이용하면 하나의 Target에 대해 여러 개의 Anchor가 매칭이 되는데 이게 Positive/Negative 비율에 영향을 주기 때문에 학습에 큰 영향이 있는 게 아닐까요? 만약 Positive/Negative 비율이 중요하다면 Anchor의 Ratio 자체는 별로 중요한 게 아니지 않을까요?
ATSS (CVPR 2020)
이러한 관점 아래, 위 논문은 Anchor-based 아키텍처와 Anchor-free 간의 차이점을 분석하면서 Anchor라는 개념이 과연 Object Detection에 필수적인 것인지 질문을 던집니다.
본 논문은 Anchor-based 아키텍처와 Anchor-free 아키텍처의 근본적인 성능 차이는 Positive, Negative Traning Sample을 정의하는 방법으로부터 비롯된다고 지적합니다. 즉, Anchor가 있든 없든 간에, 다른 말로 Box로부터든 Point로부터든 Regression을 하든지 간에 Positive, Negative Training Sample을 동일한 방식으로 정의한다면 유의미한 성능 차가 없다는 것입니다.
이는 다른 말로, Positive Training Sample과 Negative Traning Sample을 어떻게 정의하느냐가 현재 Object Detection에서 매우 중요하다는 것을 의미합니다. 이러한 문제는 Label Assignment Problem으로 불리며 이후 적절한 Positive, Negative Training Sample을 어떻게 정의할 것인지 여러 후속 연구가 이어지게 됩니다.
본 논문은 먼저 간단하게 One-stage Object Detector 중 Anchor-based 아키텍처의 대표격인 RetinaNet과 Anchor-free 아키텍처의 대표격인 FCOS 간의 구현 차이점들을 맞춰주고, Anchor 자체에 대한 성능 차이를 확인합니다.

여기서 하나의 픽셀에 여러 Anchor가 할당되는 것의 효과성을 분석하기에 앞서, Anchor 유무의 효과성 자체에 초점을 맞추기 위해 RetinaNet은 한 좌표에 Anchor가 하나만 할당되게 설정하여 실험하였습니다. 이러한 다른 모든 세팅을 맞췄음에도 불구하고 아직 FCOS와 RetinaNet은 0.8%의 차이가 있는 것을 확인할 수 있습니다.
그렇다면 이러한 차이는 어디서 발생하는 걸까요? Anchor를 쓰느냐 안 쓰느냐는 1) Positive Sample과 Negative Sample의 정의, 2) Anchor Box에서 Regression하느냐, Anchor Point에서 Regression하느냐의 차이가 아직 남아있습니다.
1) Definition of Positive & Negative Sample in Anchor-based & Anchor-free Object Detector

위에서 했던 내용을 돌이켜 봅시다. Anchor-based 아키텍처는 Positive, Negative Sample을 정의할 때 각 Anchor와 Ground-Truth의 IoU를 계산하여 특정 threshold 이상은 Positive Sample로 특정 threshold 이하는 Negative Sample로 정의합니다.
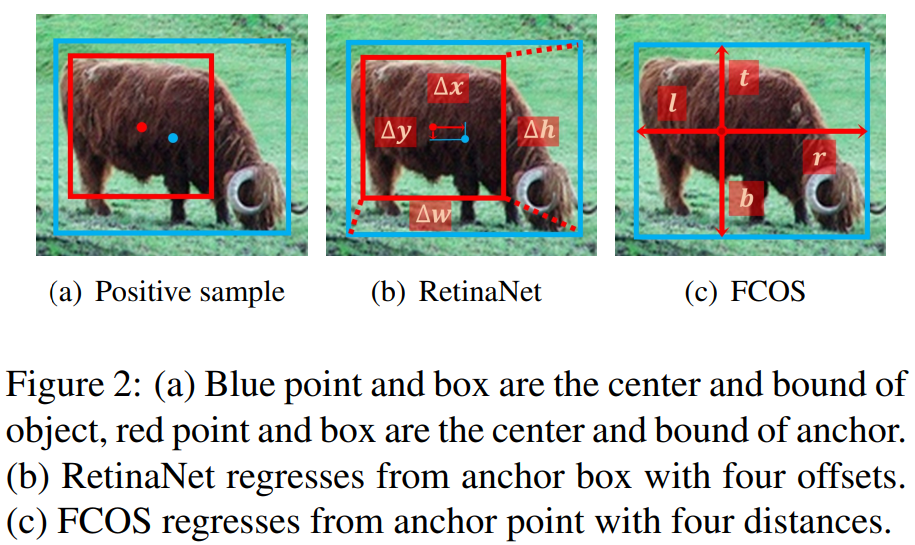
Anchor-Free 아키텍처 중 FCOS의 경우 일반적으로 해당 Object의 Bounding Box가 포함되는 위치들, 정확히는 해당 Bounding Box가 Pixel의 정중앙 좌표를 포함할 때 해당 영역을 Positive Sample로 분류하고, 나머지는 Negative Sample로 분류합니다(Spatial Constraint). 추가적으로 FCOS는 Feature Pyramid Level 별로 서로 다른 크기의 Annotation을 할당하기 때문에, 사전에 정의한 Scale과 Annotation의 크기가 맞지 않는 Pyramid Level에선 모두 Negative Sample로 할당합니다(Scale Constraint).

두 아키텍처의 Positive & Negative Training Sample 정의를 서로 다른 아키텍처에 적용한 결과 위 테이블과 같습니다. Intersection over Union은 Anchor-based Architecture의 Sample 정의 방법이며, Spatial and Scale Constraint는 FCOS의 Sample 정의 방법입니다. (Intersection over Union & Box)이 RetinaNet이며, (Spatial and Scale Constraint & Point)가 FCOS입니다.
위 테이블에서 확인할 수 있듯이, Anchor Box를 이용해 Regression하든 Anchor Point를 이용해 Regression하든지 간에 같은 방식으로 Positive & Negative Training Sample을 정의했을 때 사실상 성능이 동일하다는 것을 확인하실 수 있습니다.
2) Adaptive Training Sample Selection
본 논문은 여기서 결국 Positive & Negative Training Sample을 어떻게 정의하느냐가 Object Detection 성능에 핵심적인 역할을 한다는 것을 지적하며 Hyperparameter에 상대적으로 덜 의존적인 새로운 Sample 정의 방법을 제안합니다.

제안하는 방법은 간단합니다. 특정 Hyperparameter(IoU Threshold, Scale Constraint)에 의해 Positive, Negative를 정의하기보다는 해당 Object의 Statistics(여기선 Candidate 간의 IoU의 mean & standard deviation)을 이용해서 Positive Training Sample인지 Negative Training Sample인지 정의하자는 것입니다.
간단하게 훑어보자면, Anchor Box와 Target Object 간의 Center Distance가 가장 가까운 k개의 Anchor들을 Candidate로 고르고, 해당 Anchor와 GT 간의 mean & standard deviation을 계산하여 mean + std 값을 Positive Sample의 IoU Threshold로 활용한다는 것입니다. 마지막으로 Center가 Target Object의 Bounding Box 안에 포함되지 않은 Candidate를 필터링해줍니다.
Center Distance 같은 경우 다소 직관적인 의미이기 때문에 설명을 패스하고, mean + std 의 의미에 대해서만 살짝 언급해보겠습니다.
IoU의 mean이 상대적으로 높다면 해당 Object에 대해서 전체적으로 Anchor(Candidate)의 IoU가 높으니 상대적으로 높은 IoU의 Candidate만을 Positive Sample로 정의하는 게 바람직하다는 것을 의미합니다. 반대로 IoU의 mean이 상대적으로 낮다면 어떻게든 해당 Object를 학습하기 위해 Candidate에 대한 IoU Threshold를 낮출 필요성이 있다는 것을 의미합니다.
IoU의 standard deviation이 높다는 건 다른 말로 Pyramid Level에 따라 IoU가 큰 편차를 가진다는 의미이므로, 해당 Object를 학습할 적절한 크기의 Pyramid Level이 있다는 것을 의미합니다. 이러한 경우엔 해당 Pyramid Level의 Candidate만을 Positive로 활용하기 위해 IoU Threshold를 높여 적합하지 않은 대다수의 Candidate들을 필터링할 수 있을 것입니다. 반면 standard deviation이 낮다면 여러 Pyramid Level에 대하여 적절한 IoU를 가진다는 의미이기 때문에 여러 Pyramid Level에서 학습해도, 다른 말로 낮은 IoU Threshold로 여러 Candidate들을 Positive로 분류해도 무방하다는 것을 의미합니다.
이와 관련하여 다양한 Ablation Study를 진행하였지만 자세한 내용은 해당 논문에서 확인하시길 바라며, 본 글에서는 주요 결과만을 살펴보도록 하겠습니다.

제안한 방법을 적용할 때 RetinaNet이든 FCOS든 거의 비슷한 성능을 내는 것을 확인할 수 있습니다.

또한 해당 방법을 적용하면 Anchor의 개수나 Aspect Ratio에 강인함을 보이며 사실상 Anchor 자체가 Object Detection에 필수적인 장치가 아님을 지적합니다.

마지막으로 본 논문은 일반적으로 성능이 높다고 알려져 있는 anchor-based two stage 아키텍처를 포함한 당시 SOTA인 여러 아키텍처와 비교하며, One-stage Object Detection 모델로서 당시 COCO AP 50을 넘는 성능을 보여주었습니다.
ATSS는 CVPR 2020에 Oral을 받고 Best Paper에 Nomination되면서, 중구난방의 Object Detection 연구 흐름 속에서 Positive & Negative Training Sample을 어떻게 정의해야 하는가라는 Label Assignment을 중요 문제로서 대두시켰습니다. 또한 One-stage Detector로서 Two-Stage Detector에 준하거나 뛰어넘는 성능을 보이며 Anchor-based 와 Anchor-Free, Two-Stage Detector와 One-stage Detector 간에 널리 알려져 있는 Stereotype을 깨부수기도 하였습니다.
마무리하며
본 글에선 Object Detection을 다양한 방식으로 정의하기 위한 노력들과, 상이한 Object Detection의 접근 방법들을 Label Assignment로 정의하여 Object Detection의 성능에 필수적인 요소가 무엇인지를 밝히려는 논문을 살펴보았습니다. 저는 본 글을 통해 Object Detection 문제가 단순히 Engineering으로서의 문제가 아닌, 문제점을 정의하고 이를 해결할 Solution을 제안할 수 있는 연구적인 주제로서 연구자분들이 바라보길 바라는 마음으로 글을 작성하였습니다. 이번에 주로 다룬 2019~2020년뿐만 아니라 2021년에도 Object Detection과 관련해 다양한 연구적인 발전이 이루어졌으며, 다음 글에서 관련 연구들을 소개해보도록 하겠습니다.
SI Analytics는 위성영상에서의 Object Detection을 중요한 문제로 다루고 있으며 이와 관련된 연구적, Engineering적, MLOps적인 다양한 관점들을 통해 접근하여 해결하려 하고 있습니다. Object Detection에 몸 담고 있는 다양한 연구자, 엔지니어들의 관심과 교류를 기다리고 있도록 하겠습니다. :)
[##이학진##]
'Review' 카테고리의 다른 글
| "Weather AI solution predict future climate crisis" (0) | 2023.12.05 |
|---|---|
| “기상·기후 AI 솔루션으로 극복하는 기후 위기” (0) | 2023.12.05 |
| 시간에 따른 도시 개발을 추적해봅시다 - SpaceNet 7 수상자 기술 분석 (0) | 2021.06.03 |
| Score-based Generative Modeling by Diffusion Process (4) | 2021.02.15 |
| 라벨 스무딩(Label smoothing), When Does Label Smoothing Help? (2) | 2020.07.15 |



