
이상 탐지(Anomaly Detection)는 정상 데이터들과 큰 차이를 갖는 이상치(Anomaly)를 탐지하는 문제로 최근 딥 러닝을 이용해 해결하려는 연구가 많이 진행되고 있습니다. 이상치는 정상적인 패턴에서 벗어나 예상되는 패턴을 따르지 않는 개체를 의미하며, 오류로 인해 야기되기도 하지만 알려지지 않은 새로운 발견을 찾아내는 근거가 되기도 합니다. 따라서 이상 탐지는 사이버 보안, 의학, 금융, 행동패턴, 자연과학 및 제조업 등 다양한 산업 분야에서 활용될 수 있으며 최근 놀라운 성능 향상을 이끈 딥 러닝과 결합해 탁월한 성과를 낼 것으로 기대되고 있습니다.
본 논문에서는 딥 러닝 모델을 통해 추출한 특징(deep learning features)과 전통적인 이상 탐기 기법인 One-Class SVM을 결합한 하이브리드 방법과 비교해, 오토인코더(Autoencoder)와 Feed-Forward Neural Network를 결합한 이상 탐지 방법를 제안했습니다. 아래 그림은 논문에서 제안한 One-Class Neural Networks (OC-NN) 모델의 구조입니다.

제안하는 모델은 $(\text{a})$ 그림에서 보이는 것과 같이 먼저 입력의 대표적인 특징을 얻기 위해 오토인코더를 학습시킵니다. 이후, $(\text{b})$ 이렇게 학습된 인코더를 이용하여 원본 이미지로부터 특징을 추출한 뒤, 이를 하나의 은닉층을 갖는 Feed-Forward Neural Network에 입력으로 이용하여 이상 탐지를 시도하였습니다.
오토인코더는 입력을 압축한 다음 다시 복원하는 구조로, 원하는 출력값이 입력값과 같기 때문에 레이블링 없이 입력의 특징을 학습할 수 있습니다. 예를 들어 정상 샘플만을 이용해 학습한 오토인코더에 정상 샘플을 넣어주면 입력과 유사한 결과를 산출할 것입니다. 하지만 이렇게 학습된 오토인코더에 정상 샘플이 아닌 이상치를 넣었을 때, 원본인 이상치가 아닌 정상 샘플과 같이 복원하고, 이로 인해 입력과 출력의 차이가 커져 이상치를 탐지할 수 있습니다.
1. One Class Neural-Network
One-Class classification은 정삼 샘플만을 이용해 모델을 학습한 후, 정상 샘플과 거리가 먼 샘플을 이상치로 탐지하는 준지도(Semi-supervised) 학습 방법을 사용합니다. 이러한 경우에는 학습 데이터셋이 정상 샘플로만 이루어져 있지만, 본 논문에서 제안하는 방법은 Autoencoder를 적용하기 때문에 대다수의 정상 샘플과 극소수의 이상치가 혼재된 학습 데이터셋을 사용하는 비지도(Unsupervised) 방식으로도 학습할 수 있습니다.
만약 이상치 데이터가 충분히 확보된다면 정확도가 높은 지도(Supervised) 학습 모델을 이용하여 일반적인 분류 모델과 같은 방법으로 문제를 해결하는 것이 가장 좋습니다. 하지만 대부분은 이상치에 대한 정보가 없거나, 수집하기에는 큰 비용이 소모되기 때문에 비지도 학습이나 준지도 학습으로 많은 연구가 진행되고 있습니다.
본 논문의 기본적인 아이디어는 학습 과정을 통해 정상 샘플의 특징을 학습하고, 이 정상 특징에서 벗어나면 정상이 아닌 것으로 분류하는 것으로, 정상인지 이상치인지 결정하는 최적의 결정 경계(Decision Boundary)를 찾는 것이 중요합니다.
위에서 제안된 OC-NN은 아래의 목적 함수를 이용해 학습됩니다.

위 식에서 $r- \big <w. g(V \mathbf{X_{n:}}) \big> $ 은 정상 샘플과 이상치의 경계를 결정하는 함수(Decision Function)이며, $r$은 원점으로부터 hyperplane $w$까지를 나타내는 거리를, ν는 0과 1사이의 값으로 원점으로부터 hyperplane까지의 거리와 정상 샘플 영역의 크기 간에 trade-off를 제어하는 매개 변수입니다.
여기서 $ g(V \mathbf{X_{n:}}) $ 는 원본 데이터를 간단한 classifier로 분리하기 위한 feature mapping function으로, $\big< w. g(V \mathbf{X_{n:}}) \big> $를 통해 최종적으로 이상치 여부를 결정하는 거리를 계산합니다. 이 부분이 OC-SVM과의 차이를 나타내는 중요한 부분이라고 논문에서 설명하고 있습니다. OC-SVM은 feature mapping function으로 $\mathbf{\Phi}$ reproducing kernel Hilbert Space(RKHS)를 사용하고 있으며, OC-NN은 이 부분을 Neural Network으로 대체한다는 점이 큰 차이입니다.

다만 논문에서 다소 불분명하게 기술된 점이 있습니다. 해당 논문에서 w는 "the scalar output obtained from the hidden to output layer"이고, V는 " the weight matrix from input to hidden units" 이라고 설명하고 있습니다. 여기서 g는 활성화 함수를 의미하고, <>은 dot product연산을 의미합니다. 그런데 $\big< w, g(V\mathbf{X_{n:}}) \big>$에서 scalar 값 $w$와 $g(V\mathbf{X_{n:}})$의 출력값인 vector에 대해 dot product를 한다는 의미가 명확하지 않습니다. 이 부분에 대해서 저자가 공개한 github repository에 질문이 올라왔지만 저자 또한 명확한 답을 하지 못하는 것으로 보입니다. 실제 구현에서는 $w$까지 포함해 Neural Network로 대체한 것으로 추측됩니다.
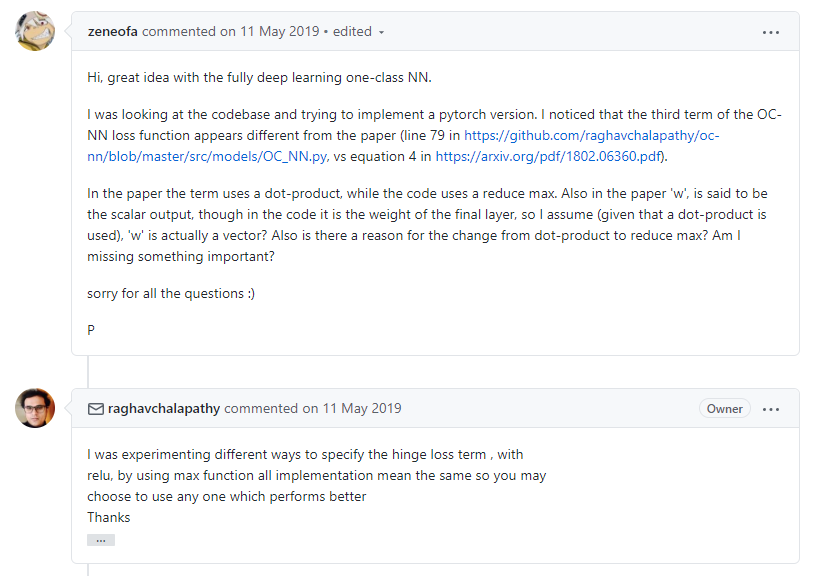
이 부분은 저자가 논문에서 정확한 수학적 설명을 하지 못한 게 아닌가 생각이 듭니다.
논문에서 중요하게 생각하는 feature mapping function의 변경(파란색$\rightarrow$빨간색)으로 OC-NN에서는 미리 학습된 인코더를 활용할 수 있게 되었습니다. 하지만 해결하고자하는 최적화 문제가 non-Convex가 되어 global optima를 찾지 못하는 문제가 생기기 때문에 아래와 같은 알고리즘을 구현하여 최적화 문제를 풀었습니다.

위에서 확인할 수 있듯이, 이 알고리즘은 가장 먼저 경계 함수의 bias인 $r$을 고정하고 $w$와 $V$에 대한 학습을 아래 식(4)로 진행하고,

새롭게 정의된 $w$와 $V$를 이용해 $r$을 아래 식 (5)로 최적화 합니다.

이 과정에서 $r$의 최적값을 찾는 경계 함수의 υ-quantile을 찾는 문제와 같아지며, 이에 대한 자세한 증명은 논문에 설명되어 있습니다. 증명 과정은 논문을 참고하시기 바랍니다.
2. Experiment and Results
실험에는 다음 5가지 데이터 셋을 사용하였습니다.
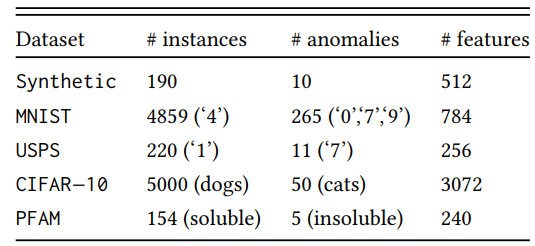
- Synthetic data: 평균은 0, 표준편차를 2로 해서 190개의 정상 샘플을 만들고 표준 편차를 10으로 해서 10개의 이상치 데이터를 생성했습니다.
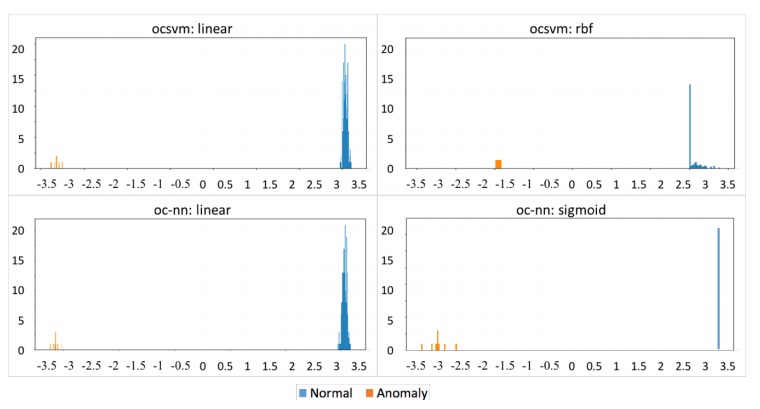
아래 그림에서 보면 이상치의 경우 경계 함수의 값이 음수이며, 기존의 OC-SVM과 유사한 성능을 보인다는 것을 확인할 수 있습니다. 표 4개 중 윗 줄이 OC-SVM결과 이고 아래가 OC-NN의 결과 입니다.
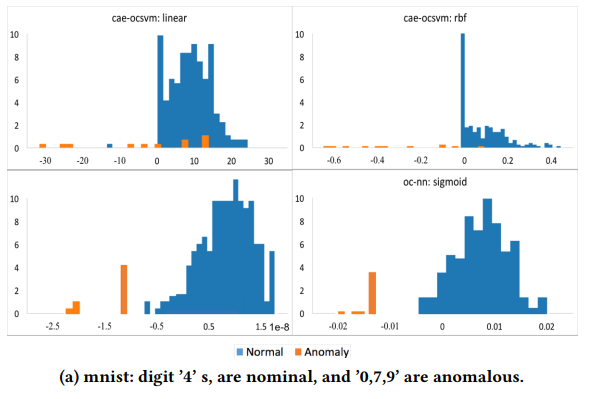
- MNIST, USPS, Cifar10: 이미지 데이터, 이상과 정상 클래스는 위 table1의 데이터셋 표 참고.
Convolution Autoencoder를 적용하였으며, 결과는 다음과 같습니다. OC-NN이 OC-SVM보다 MNIST에서는 결과가 좋고, 나머지 데이터셋에 대해서는 유사하다는 것을 확인할 수 있습니다.


- PFAM: 154개의 ‘soluble’ 단백질 배열와 5개의 ‘insoluble’ 단백질배열로 되어있는 데이터.
배열 데이터이기 때문에 LSTM 오토인코더를 적용하였으며, OC-NN이 성능이 더 좋다는 것을 확인할 수 있습니다.
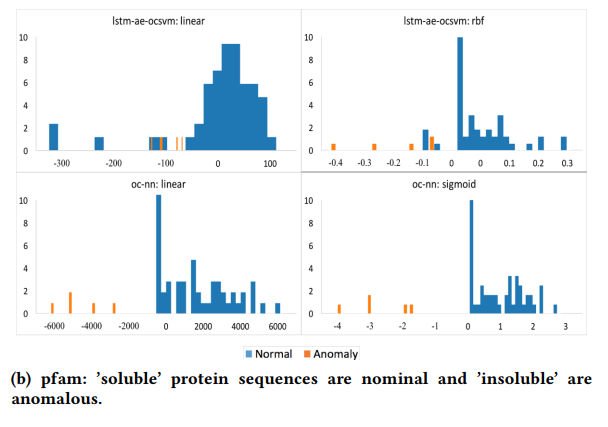
비교된 결과를 통해 확인할 수 있듯이, MNIST와 PFAM 데이터 셋에서 OC-SVM보다 OC-NN의 성능이 더 좋다는 것을 알 수 있습니다. OC-SVM 이외의 다른 방법들과도 비교한 결과는 다음과 같습니다.
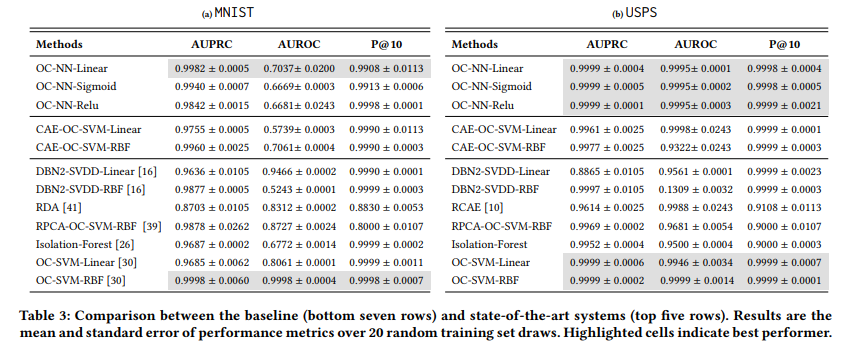

다른 방법들과 비교하여도 결론적으로 OC-NN에서 성능이 좋다는 것을 확인할 수 있습니다.
3. Conclusions
본 논문에서는 딥 러닝의 특징과 SVM을 이용하는 OC-SVM을 대체하는 오토인코더(Autoencoder)와 Feed-Forward Neural Network를 결합한 OC-NN을 제안했으며, 그 과정에서 OC-NN의 손실함수 최소화 문제가 결국 경계 함수의 quantile을 선택하는 문제라는 것을 확인하였습니다.
제안한 방법은 특정 데이터에 특화된 특징을 학습할 수 있다는 점에서, 기존에 제안된 Hybrid 방법론들과의 차이점이 있습니다. 기존 Hybrid 방법에서는 이미 학습된 딥 러닝 모델을 이용해 특징을 추출하기 때문에 추출된 특징이 이상치 탐지에 맞게 학습되었다고 할 수 없지만, 제안한 방법에서는 학습된 Autoencoder로 특징을 추출하고 다시 전이 학습(Transfer Learning)을 이용해 재학습시키기 때문에 특정 데이터의 이상치 탐지에 적합한 특징을 학습할 수 있습니다.
본 논문에서 제안한 방법은 다양한 데이터에서 기존의 방법들보다 개선된 성능을 보였으며, 구현된 알고리즘은 저자의 깃헙 페이지에 제공되는 코드를 참고하실 수 있습니다.
https://github.com/raghavchalapathy/oc-nn
[##최예지##]
'Review' 카테고리의 다른 글
| 라벨 스무딩(Label smoothing), When Does Label Smoothing Help? (2) | 2020.07.15 |
|---|---|
| Real-world Super-resolution via Kernel Estimation and Noise Injection (0) | 2020.07.15 |
| CVPR 2020 동향 분석 (0) | 2020.06.19 |
| A Benchmark for Interpretability Methods in Deep Neural Networks (0) | 2020.04.29 |
| Tutorial on Few-Shot Object Detection #2 (6) | 2020.04.21 |



